|
 |
| Information
Processing for Learning and Acquisition of Behaviors |
| |
Minoru Asada*1*2
*1Osaka Univ.,*2Handa FRC
|
Our research group at Graduate School of Engineering, Osaka University,
has been seeking for the methods of behavior learning to accomplish the
given task. The approach is not task-specific but expectant of being meaningful
from a viewpoint of information processing in our brain, and we have been
attacking several kinds of issues by constructing a model and verifying
it through real robot experiments. Summary of the following three issues
are given:
|
1. |
observation strategy learning
for decision making of small quadruped based on information theory:The
aim of this research is to propose an efficient observation strategy
for action decision of a small quadruped robot. We define the efficiency
by the time used for observation to make a decision. We compare the
contribution of the observation by the information gain. The observation
strategy we propose is to do observations in the order of the information
gain. First, we proposed a method which requires a robot to stand
still to observe and make a decision. Then, we proposed an extension
which enables observation during walking motion. |
|
2. |
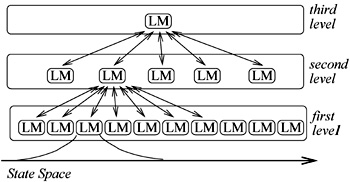
multi-layered learning systems
for vision-based behavior acquisition of a real mobile robot:We
proposed a mechanism which constructs learning modules at higher layers
using a number of groups of modules at lower layers. The modules in
the lower networks are self-organized as experts to move into different
categories of sensor value regions and learn lower level behaviors
using motor commands. In the meantime, the modules in the higher networks
are organized as experts which learn higher level behavior using lower
modules. We applied the method to a simple soccer situation in the
context of RoboCup, and showed the the validity of this method. |
|
3. |
vision-based reinforcement
learning for humanoid behavior generation with rhythmic walking parameters:A
method for generating vision-based humanoid behaviors by reinforcement
learning with rhythmic walking parameters is given. A rhythmic motion
controller such as CPG or neural oscillator stabilizes the walking.
The learning process consists of building an action space with two
parameters (a forward step width and a turning angle) so that infeasible
combinations are inhibited, and reinforcement learning with the constructed
action space and the state space consisting of visual features and
posture parameters to find a feasible action. The method is applied
to a situation from the Humanoid RoboCupSoccer league in RoboCup,
that is, to approach the ball and to shoot it into the goal. Instructions
by human are given to start up the learning process, and the rest
is solely self-learning in real situations. |
|
|
|